ChPulse - The Best RealTime Data Integration Tool For ClickHouse
ChPulse continuously transfers data from traditional databases and message queues to ClickHouse in real-time, and conveniently publishes queries as HTTP APIs with AI capabilities.
Core Features
Mirror your data from traditional databases to ClickHouse in real-time with high speed, and enjoy the efficiency of modern OLAP data processing
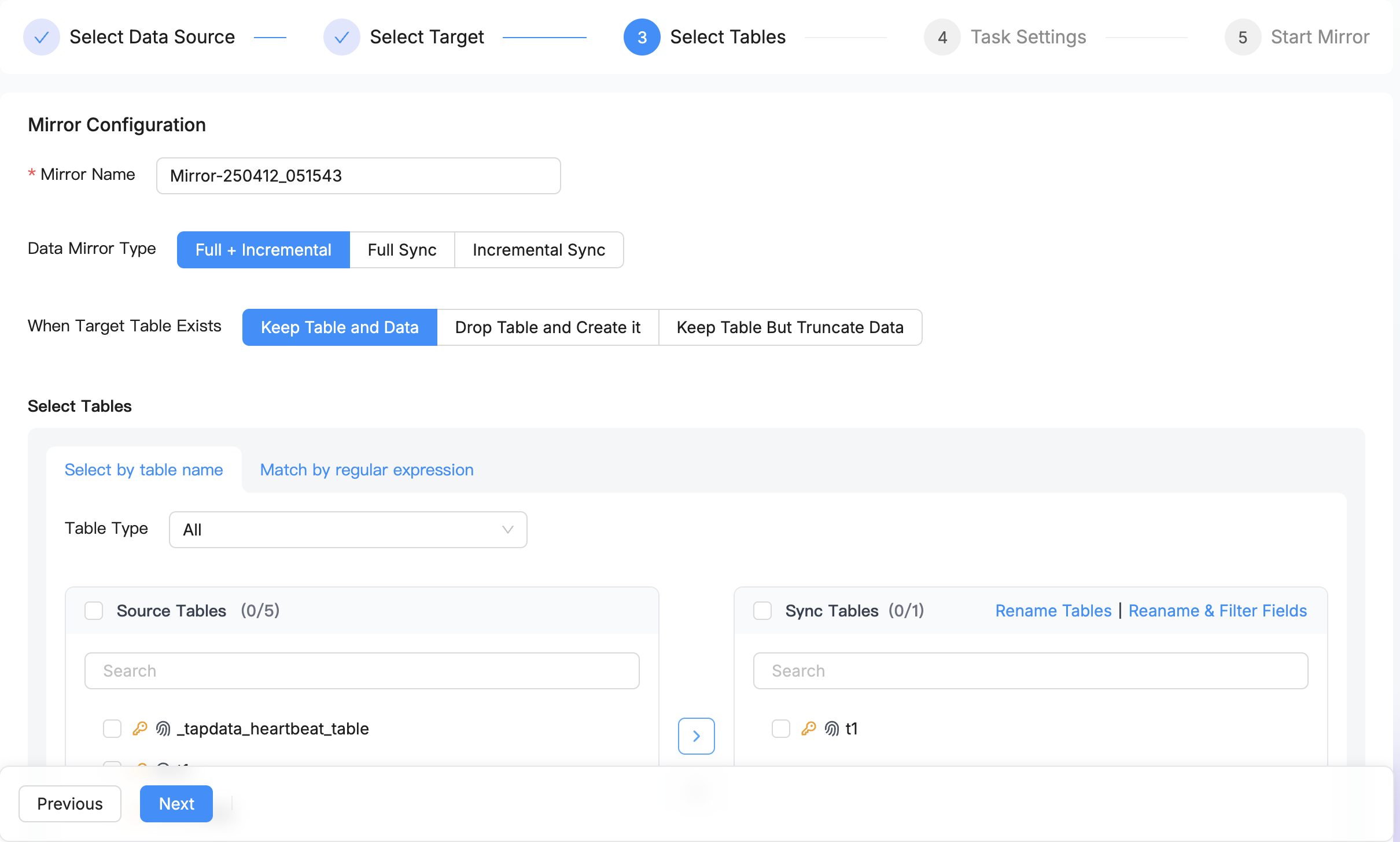
Visual End-to-End Automation
Simply select which tables to synchronize, and the entire process - including automatic table creation, full data sync, real-time incremental sync, DDL changes, and automatic sync of new tables - is handled automatically through an intuitive visual interface. No specialized knowledge required.
Comprehensive Database Support
Beyond MySQL and PostgreSQL, ChPulse supports Oracle, SQL Server, Sybase, DB2, IRIS, MongoDB document databases, and Kafka message queues - making it the most versatile data synchronization solution available.

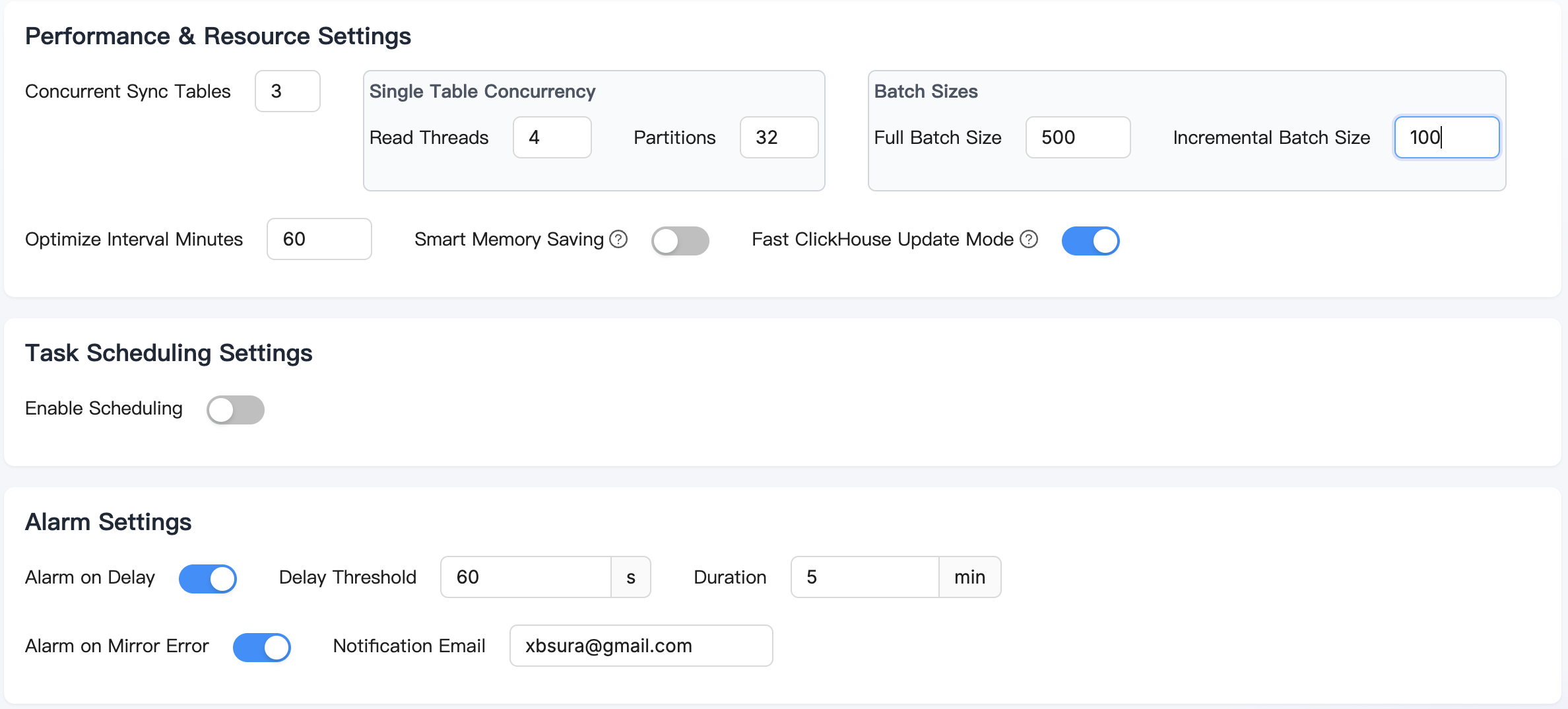
Ultra-Fast Data Mirroring
Achieve maximum performance with multi-table concurrent reading, single-table sharded reading, and optimized update operations specifically designed to overcome ClickHouse's update limitations, ensuring consistent high-speed performance.
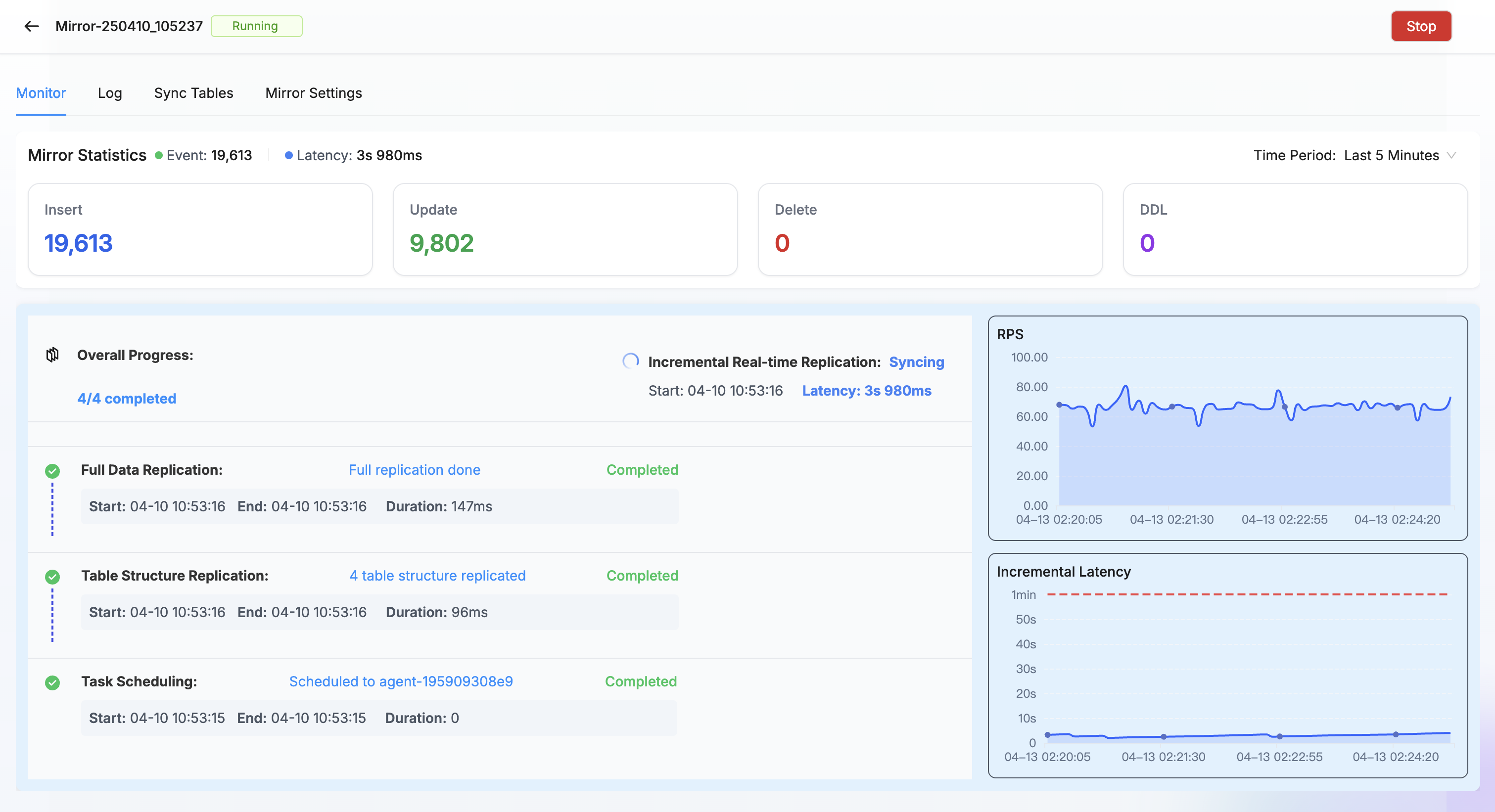
Minimal Real-Time Sync Latency
Our sync engine reads database logs, processes them in memory, and applies changes in batches to ClickHouse. This efficient design keeps data latency under 10 seconds for most real-time mirroring tasks.
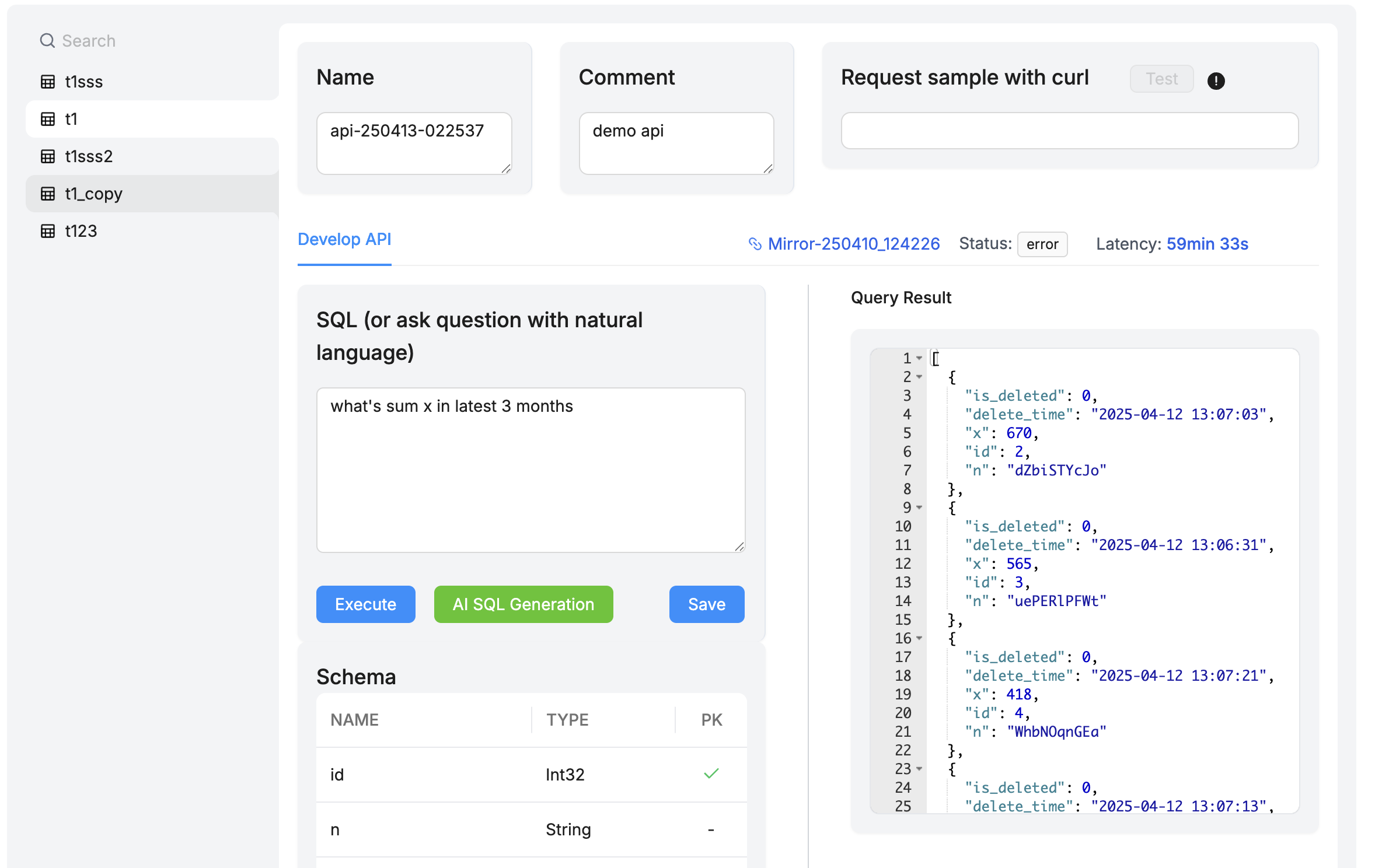
AI-Powered HTTP API Creation
After mirroring data to ClickHouse, easily leverage AI capabilities to build data query SQL and expose it as HTTP services for other business applications, truly delivering data-as-a-service.
On-Premises Database Support
Whether cloud-based or on-premises, all databases can be mirrored by deploying a lightweight sync engine in your private network. Your databases never need to be exposed to public networks, ensuring both security and performance.
Supported Connectors
All connectors have been rigorously tested and support both full and real-time incremental data synchronization












Complete Real-Time Data Mirroring in Four Steps
With just four simple operations, you can establish real-time data mirrors in ClickHouse
1
2
3
4
Frequently Asked Questions
ChPulse supports all major relational databases including MySQL, PostgreSQL, Oracle, SQL Server, and MariaDB, as well as message queues like Kafka and RabbitMQ.
ChPulse uses Change Data Capture (CDC) technology to detect changes in source systems and immediately propagate those changes to ClickHouse, ensuring millisecond-level latency.
No, ChPulse provides a visual interface for creating data pipelines without coding. However, for advanced transformations, you can use built-in processors if needed.
ChPulse is specifically designed for ClickHouse's columnar storage model, ensuring optimal data structure and performance for analytical queries.
Yes, ChPulse works seamlessly with ClickHouse in any environment - cloud, on-premises, or hybrid deployments.
ChPulse optimizes data structures for ClickHouse's columnar format and provides real-time updates, significantly improving query performance for analytical workloads.
Yes, we offer a free trial that allows you to explore all features and build your first data pipelines without any commitment.